
linux系统性能监控与优化
最近看了一下这本书《linux system and performance monitoring》,写的太好了,仔细看了一遍,下面的是读书笔记和个人的一些体会。
一,简介:
1.性能优化
性能优化的过程就是打到系统的瓶颈,并且消除这处瓶颈的过程。对于操作系统来说,就是在4个子系统(CPU,Memory,IO,Network)之间达到平衡和取舍。
不同子系统之间会相互影响,某一个子系统过高的使用率,会导致问题:
1)大量的页调入请求会填满队列
2)网卡设备上大量的吞吐,会导致CPU load过高
3)管理空闲内存队列也会消耗CPU
4)大量的磁盘写请求,会消耗CPU和IO带宽
2.应用类型
要找到系统瓶颈,应该先了解应用类型:
1)IO密集型
大量消耗内存和存储系统,对CPU和网络(存储系统是基于网络的除外)要求不高。这种应用使用CPU来发起IO请求,然后进入sleep状态。比如数据库。
2)CPU密集型
需要CPU进行批处理和数学计算。比如:web servers,mail servers,rendering server
3.找系统性能瓶颈的方法:
最好的找性能瓶颈的方法,是先对在正常满足性能要求的情况下,统计系统的各个参数,做为baseline.
然后在高压力下,当系统性能满足不了需求时,与baseline进行对比,找到性能问题。
4.常用的性能监控工具:
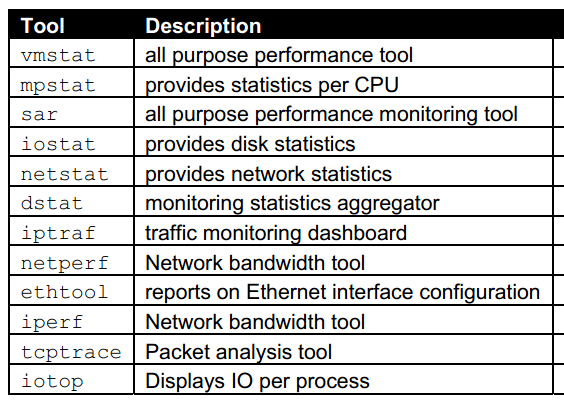
二.CPU
cpu scheduler负责调度两种资源:线程和中断
按优先级从高到低:
1)中断:设备告诉内核它们已经处理完成:如网卡发送完成了一个packet或是硬盘完成了一个io请求。
2)内核进程:
3)用户进程:
1. context switches:上下文切换
大多数的处理器在同一时刻只能运行一个进程,在多核处理器中,linux内核将每一个core当作一个独立的处理器。
一个内核可以同时运行50~50000个进程。如果只有一个cpu,内核必须负责高度和平衡这些进程。
每个线程将会分配一个时间片,直到这个线程的时间片用完,或是被更高优先级的线程抢占,它才会被重新放回cpu队列。切换线程的过程就是context switch。
每进行一次context switch,就要花费一些资源来将处理CPU寄存器和加入cpu队列。context switch越高,则内核调度的工作负担越大。
2.run queue
每个cpu都有一个运行队列。线程,要么在sleep状态(阻塞并等待IO),要么在运行状态。运行队列越长,则等待cpu处理这个线程的时间越长。
load就是用来描述运行队列的。它的值等于当前正在处理的线程+运行队列里面的线程。
比如当前系统核数是2,有两个线程正在执行行,还有4个线程在运行队列里面,那么它的load=2+4
3.cpu utilizaion
CPU的利用率。包含:
user time: 用户空间的使用时间
system time: 内核空间的使用时间
wait io: 等待IO的时间(阻塞并等待IO)
idle: 空闲时间
4.cpu性能监控
正常情况下的值:
run queues: 每个处理器的run queue长度要<=3
cpu利用率:
56%-70%的user time
30%-35%的system time
0%-5%的idle time
context switches:这个值与cpu利用率相关
5.cpu性能监控相关工具
vmstat,mpstat:
[root@zhilong ~]# vmstat 1 #每隔一秒输出
procs ———–memory———- —swap– —–io—- –system– —–cpu—–
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 789216 53288 57672 0 0 14 1 12 9 0 0 100 0 0
0 0 0 789216 53288 57672 0 0 0 0 25 15 0 0 100 0 0

6.性能排查实例
实例1:

高的中断数量,少的上下文切换数量,说明是单个进程在访问硬件设备。
user time消耗了85%的时间,并且上下文切换少说明是可能是单个应用造成的。
实例2:

上下文切换大于中断,说明上下文切换花费的时间过多。
wa过多,表示是在等待IO。
可能是因为大量线程等待IO,需要将线程切换出去。
实例3:
CPU0,CPU1正在处理cpu密集型的进程
CPU2空闲
CPU3处理内核和其它系统函数

ps -psr可以看到哪些进程在哪个核心运行
ps -eo pid,ni,pri,pcpu,psr,comm
7.总结:
1)每个核的run queue <=3
2)cpu利用率:用户空间(70%)内核空间(30%)
3)如果内核空间战用过多,很可能是负荷过重,内核花太多的资源在进行优先级调度
4)running CPU bound process(绑定CPU) always get penalized while I/O process are rewarded;?
三,Memory
虚拟内存以页的方式管理,一般为4K,如果配置了大页,则为2M
The Page Frame Reclaim Algorithm.(PFRA)
PFRA根据页的类型来释放内存。
1.页类型:
1)不能释放的页:加锁的页,内核页,保留的页
2)可交换的页:匿名内存页
3)同步的页:有对应磁盘文件的页
4)可废弃的页:static pages discarded pages
除了第一种页不能回收,其它都可以被PFRA回收。
2.PFRA主要由两种机制:
1)kswaped内核线程
2)pdflush内核线程
3.kswapd
kswapd守护线程的功能是保证有足够多的空闲内存可用。当当前系统的可用内存低于pages_low时,kswapd进程将一次释放32个页,直到空闲内存到达pages_high
相应的机制是通过一个双LRU链表来实现的。
如是这个页没有改动,则将这个内存页放到free list。如果这个页改动了,并且有对应的文件系统,将把这个页刷到磁盘。如果这个页改动了,但是匿名页,则将这个页写的swap区
4.pdflush
pdflush将对应文件系统脏页,刷到磁盘。
当内存中10%的页是脏页的话,pdflush将开始将脏页同步到文件系统,可以调整这个参数的值:vm.dirty_background_ratio
5.vmstat与内存相关的参数

6.实例:

通过下面的分析可以得出结论:io应用突然上涨,大量使用虚拟内存
1)大量的磁盘块映射到page(bi)
2)空闲内存(free)维持在17M
3)为了保持free list,kswapd从buffer获取内存,加到free list。
4)kswapd进程将dirty pages写到swap。(swpd)
7.总结:
1)缺页错误。
2)大量使用swap设备,则系统内存短缺
四,IO
IO子系统一般是linux系统中最慢的部分。一个原因是它距离CPU的距离,另一个原因是它的物理结构。访问磁盘的时间与访问内存的时间是7天与7分钟的区别。linux kernel要尽量减少磁盘IO。
1.Reading and Writing Data
linux内核以page为单位访问磁盘IO,一般为4K。
查看页大小:/usr/bin/time -v date
Page size (bytes): 4096
2.Major and Minor Page Faults
linux会将内存物理地址空间映射到虚拟内存,内核仅会映射需要的内存页。当应用启动时,内核依次搜索CPU cache和物理内存,查找是否有相应的内存页,如果不存在,则内核将会发起一次MPF(major page fault),将磁盘中的数据读出并缓存到内存中。
如果在buffer cache找到了对应的内存页,则将会产生一个MnPF(minor page fault).
/usr/bin/time -v helloworld
第一次执行会发现大部分是MPF
第二次执行会发现大部分是MnPF
3.The File Buffer Cache
file buffer cache用来减少MPF,增加MnPF,它将会持续增长,直到可用内存比较少或是内核需要为其它应用来释放一些内存。free内存比较少,并不能说明系统内存紧张,只能说明linux系统充分使用内存来做cache.
cat /proc/meminfo
MemTotal: 24730888 kB
总内存
MemFree: 2633168 kB
空闲内存
Buffers: 2191776 kB
写buffer(这里有问题吧,应该是block cache吧)
Cached: 15879728 kB 读cache
4.内存页的类型
read pages: 只读的页,并且在磁盘中有对应文件,一般是静态文件,二进制文件,库。当内存短缺时,这些页可以直接丢弃,放到free list.
dirty pages: 在内存中被修改的页,需要使用pdflush/kswapd刷回磁盘。
anonymous pages: 属于某个进程的内存,但在磁盘中没有对应的文件,当内存短缺时,要写到swap
5.将数据页写回磁盘
可以使用fsync()或是sync()立即写回,如果没有直接调用这些函数,pdflush会定期刷回磁盘。
6.监控IO的工具
top,vmstat,iostat,sar
10万转速的磁盘,一般的响应时间是8ms,可以达到120~150IOPS.
7.顺序IO与随机IO
8.iotop可以显示所有应用的IO占用情况
9.总结
一旦CPU在等待IO,说明磁盘负载过重
计算磁盘可以承受的IOPS
顺序IO与随机IO
监控慢盘的等待时间和服务时间
监控swap.
转载请注明:崔之龙–运维小崔的个人博客 » linux系统性能监控与优化
还没有人抢沙发呢~